The Java Dependency Analysis tool, jdeps, is a versatile command-line tool for static analysis of dependencies between Java artifacts like class files and JARs. It can analyze dependencies at all levels: module, package, and class. It allows the results to be filtered and aggregated in various ways, even generating various graphs to illustrate its findings. It is an indispensable tool when migrating non-modular code to make use of the module system.
In this section, we confine our discussion to modular code—that is, either an exploded module directory with the compiled module code (e.g., mods/main) or a modular JAR (e.g., mlib/main.jar).
In this section, the results from some of the jdeps commands have been edited to fit the width of the page without any loss of information, or elided to shorten repetitious outputs.
Viewing Package-Level Dependencies
The jdeps command with no options, shown below, illustrates the default behavior of the tool. Line numbers have been added for illustrative purposes.
When presented with the root module directory mods/model (1), the default behavior of jdeps is to print the name of the module (2), the path to its location (3), its module descriptor (4), followed by its module dependencies (5), and lastly the package-level dependencies (6). The package-level dependency at (6) shows that the package com.passion.model in the model module depends on the java.lang package in the proverbial java.base module.
(2) model (3) [file:…/adviceApp/mods/model/] (4) requires mandated java.base (@17.0.2) (5) model -> java.base (6) com.passion.model -> java.lang java.base
The following jdeps command if let loose on the model.jar archive will print the same information for the model module, barring the difference in the file location:
> jdeps mlib/model.jar
However, the following jdeps command with the main.jar archive gives an error:
Exception in thread “main” java.lang.module.FindException: Module controller not found, required by main at java.base/…
Dependency analysis cannot be performed on the main module by the jdeps tool because the modules the main module depends on cannot be found. In the case of the model module, which does not depend on any other user-defined module, the dependency analysis can readily be performed.
The two options –module-path (no short form) and –module (short form: -m) in the jdeps command below unambiguously specify the location of other modular JARs and the module to analyze, respectively. The format of the output is the same as before, and can be verified easily.
>jdeps –module-path mlib –module main main [file:…/adviceApp/mlib/main.jar] requires controller requires mandated java.base (@17.0.2) main -> controller main -> java.base com.passion.main -> com.passion.controller controller com.passion.main -> java.lang java.base
However, if one wishes to analyze all modules that the specified module depends on recursively, the –recursive option (short form: -R) can be specified. The output will be in the same format as before, showing the package-level dependencies for each module. The output from the jdeps command for each module is elided below, but has the same format we have seen previously.
The simplest way to create a Path is to use the static factory method Path.of(String first, String… more). It joins the first string with any strings in the variable arity parameter more to create a path string that is the basis of constructing a Path object. This method creates a Path object in accordance with the default file system.
For instance, the default file system can be queried for the platform-specific name separator for name elements in a path.
The three absolute paths below are equivalent on a Unix platform, as they create a Path object based on the same path string. The nameSeparator string is the platform-specific name separator obtained from the default file system. At (1) and (2) below, only the first string parameter is specified in the Path.of() method, and it is the basis for constructing a Path object. However, specifying the variable arity parameter where possible is recommended when a Path object is constructed as shown at (3), as joining of the name elements is implicitly done using the platform-specific name separator. The equals() methods simply checks for equality on the path string, not on any directory entry denoted by the Path objects.
FileSystem dfs = FileSystems.getDefault(); // Obtain the default file system. String nameSeparator = dfs.getSeparator(); // The name separator for a path.
The two absolute paths below are equivalent on a Windows platform, as they create Path objects based on the same path string. Note that the backslash character must be escaped with a second backslash in a string. Otherwise, it will be interpreted as starting an escape sequence (§2.1, p. 38).
Often we need to create a Path object to denote the current directory. This can be done via a system property named “user.dir” that can be looked up, as shown at (1) below, and its value used to construct a Path object, as shown at (2). The path string of the current directory can be used to create paths relative to the current directory, as shown at (3).
The Java language compiler, javac, compiles Java source code into Java bytecode. The general form of the javac command is:
javac [options] [sourcefiles]
Table 19.7 shows some selected options that can be used when compiling modules. The optional sourcefiles is an itemized list of source files, often omitted in favor of using module-related options.
Table 19.7 Selected Options for the javac Tool
Option
Description
–module-source-path
moduleSourcePath
The moduleSourcePath specifies the source directory where the exploded modules with the source code files can be found.
–module-path modulepath
-p modulepath
The modulepath specifies where the modules needed by the application can be found. This can be a root directory of the exploded modules with the class files or a root directory where the modular JARs can be found. Multiple directories of modules can be specified, separated by a colon (:) on a Unix-based platform and semicolon (;) on the Windows platform.
–module moduleName
-m moduleName
Specifies the module(s) to be compiled. Can be a single module name or a comma-separated (,) list of module names. For each module specified, all modules it depends on are also compiled, according to the module dependencies.
-d classesDirectory
Specifies the destination directory for the class files. Mandatory when compiling modules. For classes in a package, their class files are put in a directory hierarchy that reflects the package name, with directories being created as needed. Without the -d option, the class files are put in the same directory as their respective source files. Specifying the directory path is platform dependent: slash (/) on Unix-based platforms and backslash (\) on Windows platforms being used when specifying the directory path.
–add-modules module,…
Specifies root modules to resolve in addition to the initial modules. These modules can be modular JAR files, JMOD files, or even exploded modules.
Selected Options for the java Tool
The java tool launches an application—that is, it creates an instance of the JVM in which to run the application. A typical command to launch a modular application is by specifying the location of its modules (path) and the entry point of the application (as module or module/mainclass):
Table 19.8 shows some selected options that can be used for launching and exploring modular applications.
Table 19.8 Selected Options for the java Tool
Option
Description
–module-path modulepath…
-p modulepath
The modulepath specifies the location where the modules needed to run the application can be found. This can be a root directory for the exploded modules with the class files or a directory where the modular JARs can be found. Multiple directories of modules can be specified, separated by a colon (:) on a Unix-based platform and semicolon (;) on Windows platforms.
When module/mainclass is specified, it explicitly states the module name and the fully qualified name of the class with the main() method, thereby overriding any other entry point in the application. Without the mainclass, the entry point of the application is given by the module which must necessarily contain the main-class.
–add-modules module,…
Specifies root modules to resolve in addition to the initial modules.
–list-modules
Only lists the observable modules, and does not launch the application. That is, it lists the modules that the JVM can use when the application is run.
–describe-module moduleName
-d moduleName
Describes a specified module, in particular its module descriptor, but does not launch the application.
–validate-modules
Validates all modules on the module path to find conflicts and errors within modules.
Java provides I/O streams as a general mechanism for dealing with data input and output. I/O streams implement sequential processing of data. An input stream allows an application to read a sequence of data, and an output stream allows an application to write a sequence of data. An input stream acts as a source of data, and an output stream acts as a destination of data. The following entities can act as both input and output streams:
A file—which is the focus in this chapter
An array of bytes or characters
A network connection
There are two categories of I/O streams:
Byte streams that process bytes as a unit of data
Character streams that process characters as a unit of data
A low-level I/O stream operates directly on the data source (e.g., a file or an array of bytes), and processes the data primarily as bytes.
A high-level I/O stream is chained to an underlying stream, and provides additional capabilities for processing data managed by the underlying stream—for example, processing bytes from the underlying stream as Java primitive values or objects. In other words, a high-level I/O stream acts as a wrapper for the underlying stream.
In the rest of this chapter we primarily explore how to use I/O streams of the standard I/O API provided by the java.io package to read and write various kinds of data that is stored in files.
20.2 Byte Streams: Input Streams and Output Streams
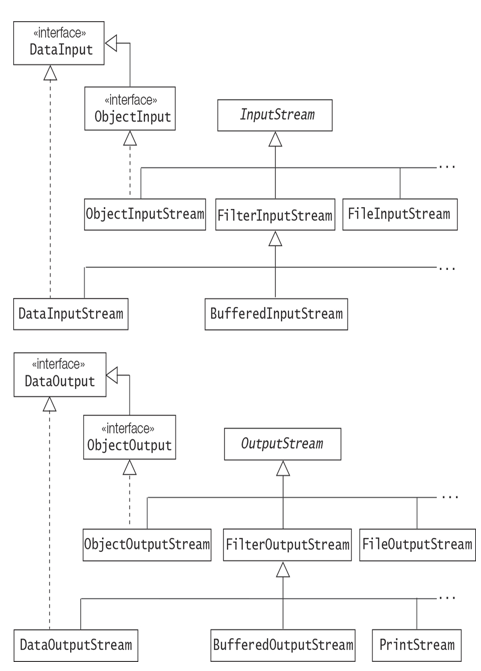
The abstract classes InputStream and OutputStream in the java.io package are the root of the inheritance hierarchies for handling the reading and writing of data as bytes (Figure 20.1). Their subclasses, implementing different kinds of input and output (I/O) streams, override the following methods from the InputStream and OutputStream classes to customize the reading and writing of bytes, respectively:
Figure 20.1 Partial Byte Stream Inheritance Hierarchies in the java.io Package
int read() throws IOException int read(byte[] b) throws IOException int read(byte[] b, int off, int len) throws IOException
Note that the first read() method reads a byte, but returns an int value. The byte read resides in the eight least significant bits of the int value, while the remaining bits in the int value are zeroed out. The read() methods return the value –1 when the end of the input stream is reached.
long transferTo(OutputStream out) throws IOException
Reads bytes from this input stream and writes to the specified output stream in the order they are read. The I/O streams are not closed after the operation (see below).
void write(int b) throws IOException void write(byte[] b) throws IOException void write(byte[] b, int off, int len) throws IOException
The first write() method takes an int as an argument, but truncates it to the eight least significant bits before writing it out as a byte to the output stream.
void close() throws IOException Both InputStream and OutputStream void flush() throws IOException Only for OutputStream
A I/O stream should be closed when no longer needed, to free system resources. Closing an output stream automatically flushes the output stream, meaning that any data in its internal buffer is written out.
Since byte streams also implement the AutoCloseable interface, they can be declared in a try-with-resources statement (§7.7, p. 407) that will ensure they are properly closed after use at runtime.
An output stream can also be manually flushed by calling the second method.
Read and write operations on streams are blocking operations—that is, a call to a read or write method does not return before a byte has been read or written.
Many methods in the classes contained in the java.io package throw the checked IOException. A calling method must therefore either catch the exception explicitly, or specify it in a throws clause.
Table 20.1 and Table 20.2 give an overview of selected byte streams. Usually an output stream has a corresponding input stream of the same type.
Table 20.1 Selected Input Streams
FileInputStream
Data is read as bytes from a file. The file acting as the input stream can be specified by a File object, a FileDescriptor, or a String file name.
FilterInputStream
The superclass of all input filter streams. An input filter stream must be chained to an underlying input stream.
DataInputStream
A filter stream that allows the binary representation of Java primitive values to be read from an underlying input stream. The underlying input stream must be specified.
ObjectInputStream
A filter stream that allows binary representations of Java objects and Java primitive values to be read from a specified input stream.
Table 20.2 Selected Output Streams
FileOutputStream
Data is written as bytes to a file. The file acting as the output stream can be specified by a File object, a FileDescriptor, or a String file name.
FilterOutputStream
The superclass of all output filter streams. An output filter stream must be chained to an underlying output stream.
PrintStream
A filter output stream that converts a text representation of Java objects and Java primitive values to bytes before writing them to an underlying output stream, which must be specified. This is the type of System.out and System.err (p. 1255). However, the PrintWriter class is recommended when writing characters rather than bytes (p. 1247).
DataOutputStream
A filter stream that allows the binary representation of Java primitive values to be written to an underlying output stream. The underlying output stream must be specified.
ObjectOutputStream
A filter stream that allows the binary representation of Java objects and Java primitive values to be written to a specified underlying output stream.
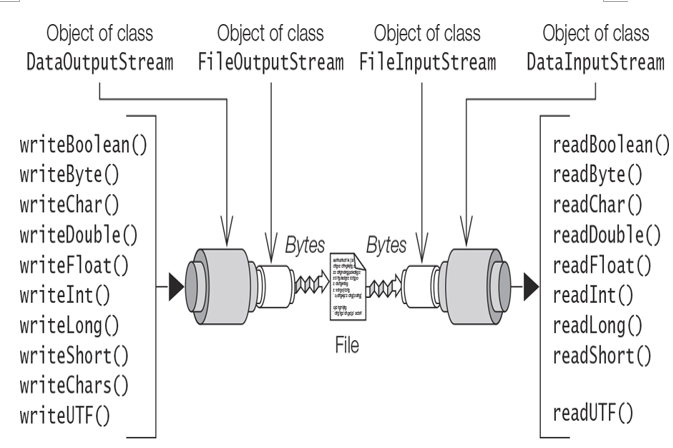
To write the binary representation of Java primitive values to a binary file, the following procedure can be used, which is also depicted in Figure 20.2.
Figure 20.2 Stream Chaining for Reading and Writing Binary Values to a File
Use a try-with-resources statement for declaring and creating the necessary streams, which guarantees closing of the filter stream and any underlying stream.
DataOutputStream outputStream = new DataOutputStream(outputFile);
Write Java primitive values using relevant writeX() methods:
Note that in the case of char, byte, and short data types, the int argument to the writeX() method is converted to the corresponding type, before it is written (see Table 20.3).
See also the numbered lines in Example 20.2 corresponding to the steps above.
Reading Binary Values from a File
To read the binary representation of Java primitive values from a binary file, the following procedure can be used, which is also depicted in Figure 20.2.
Use a try-with-resources statement for declaring and creating the necessary streams, which guarantees closing of the filter stream and any underlying stream.
DataInputStream inputStream = new DataInputStream(inputFile);
Read the (exact number of) Java primitive values in the same order they were written out to the file, using relevant readX() methods. Not doing so will unleash the wrath of the IOException.
See also the numbered lines in Example 20.2 corresponding to the steps above. Example 20.2 uses both procedures described above: first to write and then to read some Java primitive values to and from a file. It also checks to see if the end of the stream has been reached, signaled by an EOFException. The values are also written to the standard output stream.
import java.io.*; public class BinaryValuesIO { public static void main(String[] args) throws IOException { // Write binary values to a file: try( // (1) // Create a FileOutputStream. (2) FileOutputStream outputFile = new FileOutputStream(“primitives.data”); // Create a DataOutputStream which is chained to the FileOutputStream.(3) DataOutputStream outputStream = new DataOutputStream(outputFile)) { // Write Java primitive values in binary representation: (4) outputStream.writeBoolean(true); outputStream.writeChar(‘A’); // int written as Unicode char outputStream.writeByte(Byte.MAX_VALUE); // int written as 8-bits byte outputStream.writeShort(Short.MIN_VALUE); // int written as 16-bits short outputStream.writeInt(Integer.MAX_VALUE); outputStream.writeLong(Long.MIN_VALUE); outputStream.writeFloat(Float.MAX_VALUE); outputStream.writeDouble(Math.PI); } // Read binary values from a file: try ( // (1) // Create a FileInputStream. (2) FileInputStream inputFile = new FileInputStream(“primitives.data”); // Create a DataInputStream which is chained to the FileInputStream. (3) DataInputStream inputStream = new DataInputStream(inputFile)) { // Read the binary representation of Java primitive values // in the same order they were written out: (4) System.out.println(inputStream.readBoolean()); System.out.println(inputStream.readChar()); System.out.println(inputStream.readByte()); System.out.println(inputStream.readShort()); System.out.println(inputStream.readInt()); System.out.println(inputStream.readLong()); System.out.println(inputStream.readFloat()); System.out.println(inputStream.readDouble()); // Check for end of stream: int value = inputStream.readByte(); System.out.println(“More input: ” + value); } catch (FileNotFoundException fnf) { System.out.println(“File not found.”); } catch (EOFException eof) { System.out.println(“End of input stream.”); } } }
Output from the program:
true A 127 -32768 2147483647 -9223372036854775808 3.4028235E38 3.141592653589793 End of input stream.
A character encoding is a scheme for representing characters. Java programs represent values of the char type internally in the 16-bit Unicode character encoding, but the host platform might use another character encoding to represent and store characters externally. For example, the ASCII (American Standard Code for Information Interchange) character encoding is widely used to represent characters on many platforms. However, it is only one small subset of the Unicode standard.
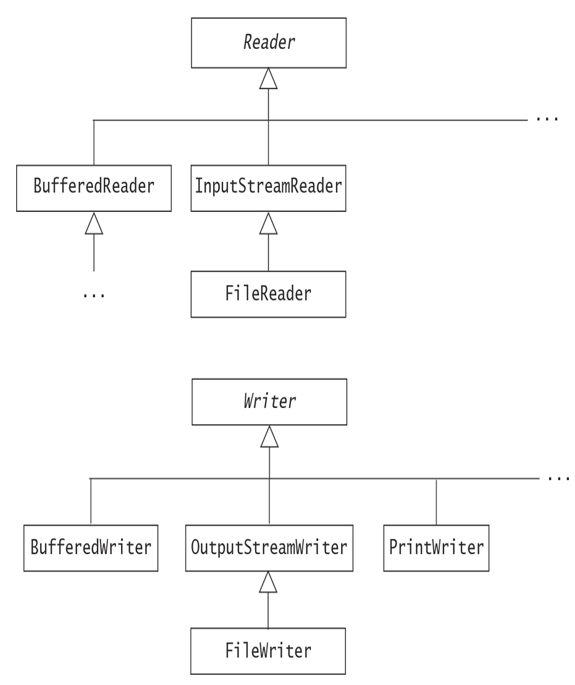
The abstract classes Reader and Writer are the roots of the inheritance hierarchies for streams that read and write Unicode characters using a specific character encoding (Figure 20.3). A reader is an input character stream that implements the Readable interface and reads a sequence of Unicode characters, and a writer is an output character stream that implements the Writer interface and writes a sequence of Unicode characters. Character encodings (usually called charsets) are used by readers and writers to convert between external bytes and internal Unicode characters. The same character encoding that was used to write the characters must be used to read those characters. The java.nio.charset.Charset class represents charsets. Kindly refer to the Charset class API documentation for more details.
Figure 20.3 Selected Character Streams in the java.io Package
Returns the default charset of this Java virtual machine.
Table 20.4 and Table 20.5 give an overview of some selected character streams found in the java.io package.
Table 20.4 Selected Readers
Reader
Description
BufferedReader
A reader is a high-level input stream that buffers the characters read from an underlying stream. The underlying stream must be specified and an optional buffer size can be given.
InputStreamReader
Characters are read from a byte input stream which must be specified. The default character encoding is used if no character encoding is explicitly specified in the constructor. This class provides the bridge from byte streams to character streams.
FileReader
Characters are read from a file, using the default character encoding, unless an encoding is explicitly specified in the constructor. The file can be specified by a String file name. It automatically creates a FileInputStream that is associated with the file.
Table 20.5 Selected Writers
Writers
Description
BufferedWriter
A writer is a high-level output stream that buffers the characters before writing them to an underlying stream. The underlying stream must be specified, and an optional buffer size can be specified.
OutputStreamWriter
Characters are written to a byte output stream that must be specified. The default character encoding is used if no explicit character encoding is specified in the constructor. This class provides the bridge from character streams to byte streams.
FileWriter
Characters are written to a file, using the default character encoding, unless an encoding is explicitly specified in the constructor. The file can be specified by a String file name. It automatically creates a FileOutputStream that is associated with the file. A boolean parameter can be specified to indicate whether the file should be overwritten or appended with new content.
PrintWriter
A print writer is a high-level output stream that allows text representation of Java objects and Java primitive values to be written to an underlying output stream or writer. The underlying output stream or writer must be specified. An explicit encoding can be specified in the constructor, and also whether the print writer should do automatic line flushing.
Readers use the following methods for reading Unicode characters:
int read() throws IOException int read(char cbuf[]) throws IOException int read(char cbuf[], int off, int len) throws IOException
Note that the read() methods read the character as an int in the range 0 to 65,535 (0x0000–0xFFFF).
The first method returns the character as an int value. The last two methods store the characters in the specified array and return the number of characters read. The value -1 is returned if the end of the stream has been reached.
When called, this method returns true if the next read operation is guaranteed not to block. Returning false does not guarantee that the next read operation will block.
Reads all characters from this reader and writes the characters to the specified writer in the order they are read. The I/O streams are not closed after the operation.
Writers use the following methods for writing Unicode characters:
Like byte streams, a character stream should be closed when no longer needed in order to free system resources. Closing a character output stream automatically flushes the stream. A character output stream can also be manually flushed.
Like byte streams, many methods of the character stream classes throw a checked IOException that a calling method must either catch explicitly or specify in a throws clause. They also implement the AutoCloseable interface, and can thus be declared in a try-with-resources statement (§7.7, p. 407) that will ensure they are automatically closed after use at runtime.
Analogous to Example 20.1 that demonstrates usage of a byte buffer for writing and reading bytes to and from file streams, Example 20.3 demonstrates using a character buffer for writing and reading characters to and from file streams. Later in this section, we will use buffered readers (p. 1251) and buffered writers (p. 1250) for reading and writing characters from files, respectively.
Example 20.3 Copying a File Using a Character Buffer
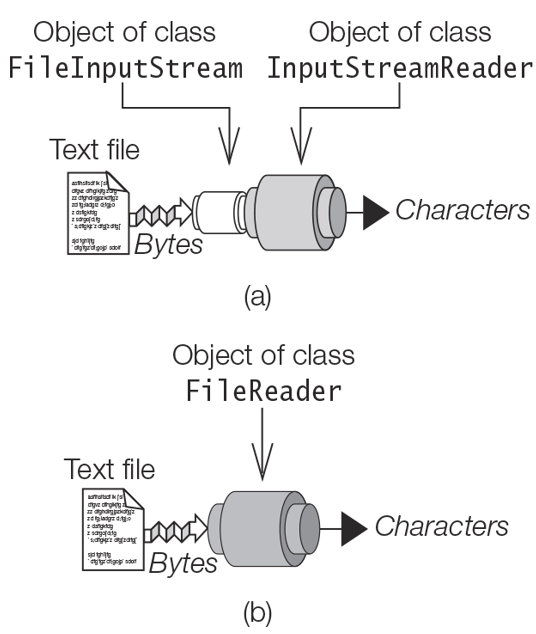
When reading characters from a file using the default character encoding, the following two procedures for setting up an InputStreamReader can be used.
Setting up an InputStreamReader which is chained to a FileInputStream (Figure 20.5(a)):
FileReader fileReader = new FileReader(“info.txt”);
This is equivalent to having an InputStreamReader chained to a FileInputStream for reading the characters from the file, using the default character encoding.
If a specific character encoding is desired for the reader, the first procedure can be used (Figure 20.5(a)), with the encoding being specified for the InputStreamReader:
Charset utf8 = Charset.forName(“UTF-8”); FileInputStream inputFile = new FileInputStream(“info.txt”); InputStreamReader reader = new InputStreamReader(inputFile, utf8);
This reader will use the UTF-8 character encoding to read the characters from the file. Alternatively, we can use one of the FileReader constructors that accept a character encoding:
Charset utf8 = Charset.forName(“UTF-8”); FileReader reader = new FileReader(“info.txt”, utf8);
A BufferedReader can also be used to improve the efficiency of reading characters from the underlying stream, as explained later in this section (p. 1251).
Using Buffered Writers
A BufferedWriter can be chained to the underlying writer by using one of the following constructors:
BufferedWriter(Writer out) BufferedWriter(Writer out, int size)
The default buffer size is used, unless the buffer size is explicitly specified.
Characters, strings, and arrays of characters can be written using the methods for a Writer, but these now use buffering to provide efficient writing of characters. In addition, the BufferedWriter class provides the method newLine() for writing the platform-dependent line separator.
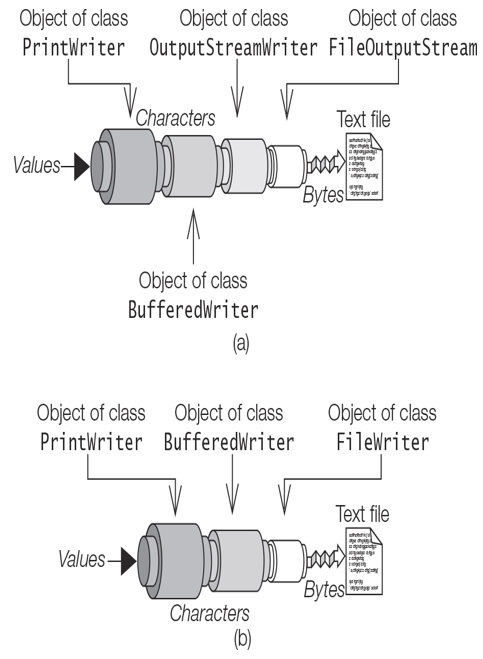
The following code creates a PrintWriter whose output is buffered, and the characters are written using the UTF-8 character encoding (Figure 20.6(a)):
Charset utf8 = Charset.forName(“UTF-8”); FileOutputStream outputFile = new FileOutputStream(“info.txt”); OutputStreamWriter outputStream = new OutputStreamWriter(outputFile, utf8); BufferedWriter bufferedWriter1 = new BufferedWriter(outputStream); PrintWriter printWriter1 = new PrintWriter(bufferedWriter1, true);
The following code creates a PrintWriter whose output is buffered, and the characters are written using the default character encoding (Figure 20.6(b)):
FileWriter fileWriter = new FileWriter(“info.txt”); BufferedWriter bufferedWriter2 = new BufferedWriter(fileWriter); PrintWriter printWriter2 = new PrintWriter(bufferedWriter2, true);
Note that in both cases, the PrintWriter is used to write the characters. The Buffered-Writer is sandwiched between the PrintWriter and the underlying OutputStreamWriter (which is the superclass of the FileWriter class).
The standard output stream (usually the display) is represented by the PrintStream object System.out. The standard input stream (usually the keyboard) is represented by the InputStream object System.in. In other words, it is a byte input stream. The standard error stream (also usually the display) is represented by System.err, which is another object of the PrintStream class. The PrintStream class offers print() methods that act as corresponding print() methods from the PrintWriter class. The print() methods can be used to write output to System.out and System.err. In other words, both System.out and System.err act like PrintWriter, but in addition they have write() methods for writing bytes.
The System class provides the methods setIn(InputStream), setOut(PrintStream), and setErr(PrintStream) that can be passed an I/O stream to reassign the standard streams.
In order to read characters typed by the user, the Console class is recommended (p. 1256).
Comparison of Byte Streams and Character Streams
It is instructive to see which byte streams correspond to which character streams. Table 20.7 shows the correspondence between byte and character streams. Note that not all classes have a corresponding counterpart.
Table 20.7 Correspondence between Selected Byte and Character Streams
Byte streams
Character streams
OutputStream
Writer
InputStream
Reader
No counterpart
OutputStreamWriter
No counterpart
InputStreamReader
FileOutputStream
FileWriter
FileInputStream
FileReader
BufferedOutputStream
BufferedWriter
BufferedInputStream
BufferedReader
PrintStream
PrintWriter
DataOutputStream
No counterpart
DataInputStream
No counterpart
ObjectOutputStream
No counterpart
ObjectInputStream
No counterpart
20.4 The Console Class
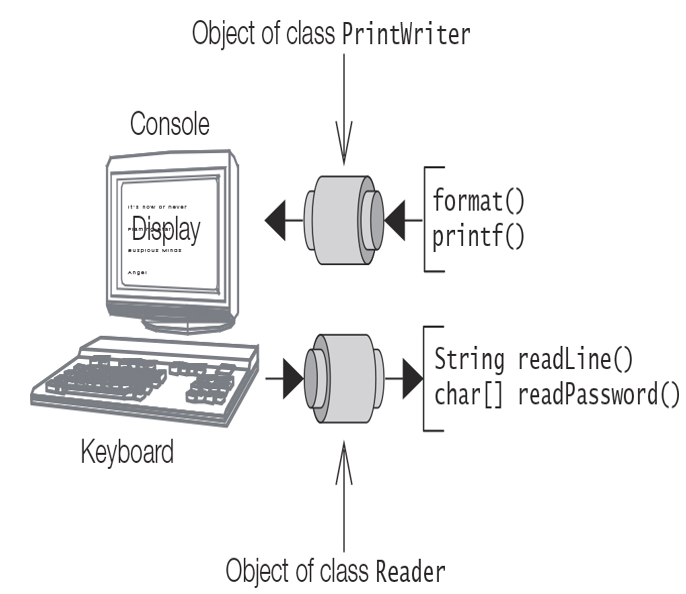
A console is a unique character-based device associated with a JVM. Whether a JVM has a console depends on the platform, and also on the manner in which the JVM is invoked. When the JVM is started from a command line, and the standard input and output streams have not been redirected, the console will normally correspond to the keyboard and the display (Figure 20.8). In any case, the console will be represented by an instance of the class java.io.Console. This Console instance is a singleton, and can only be obtained by calling the static method console() of the System class. If there is no console associated with the JVM, the null value is returned by this method.
String username = console.readLine(“Enter the username (%d chars): “, 4);
The readLine() method first prints the formatted prompt on the console, and then returns the characters typed at the console when the line is terminated by the ENTER key.
Prompt and read passwords without echoing the characters on the console.
char[] password; do { password = console.readPassword(“Enter password (min. %d chars): “, 6); } while (password.length < 6);
The readPassword() method first prints the formatted prompt, and returns the password characters typed by the user in an array of char when the line is terminated by the ENTER key. The password characters are not echoed on the display.
Since a password is sensitive data, one recommended practice is to have it stored in memory for only as long as it is necessary and to zero-fill the char array as soon as possible in order to overwrite the password characters.
Print formatted values to the console.
Similar to the PrintWriter and the PrintStream classes, the Console class also provides the format() and the printf() methods for printing formatted values, but its methods do not allow a locale to be specified.
Note that the console only returns character-based input. For reading other types of values from the standard input stream, the java.util.Scanner class can be considered.
The Console class provides methods for formatted prompting and reading from the console, and obtaining the reader associated with it.
String readLine() String readLine(String format, Object… args)
The first method reads a single line of text from the console. The second method prints a formatted prompt first, then reads a single line of text from the console. The prompt is constructed by formatting the specified args according to the specified format.
char[] readPassword() char[] readPassword(String format, Object… args)
The first method reads a password or a password phrase from the console with echoing disabled. The second method does the same, but first prints a formatted prompt.
Reader reader()
This retrieves the unique Reader object associated with this console.
The Console class provides the following methods for writing formatted strings to the console, and obtaining the writer associated with it:
Console format(String format, Object… args) Console printf(String format, Object… args)
Write a formatted string to this console’s output stream using the specified format string and arguments, according to the default locale. See the PrintWriter class with analogous methods (p. 1245).
PrintWriter writer()
Retrieves the unique PrintWriter object associated with this console.
void flush()
Flushes the console and forces any buffered output to be written immediately.
Example 20.5 illustrates using the Console class to change a password. The example illustrates the capability of the Console class, and in no way should be construed to provide the ultimate secure implementation to change a password.
The console is obtained at (1). The code at (2) implements the procedure for changing the password. The user is asked to submit the new password, and then asked to confirm it. Note that the password characters are not echoed. The respective char arrays returned with this input are compared for equality by the static method equals() in the java.util.Arrays class, which compares two arrays.
import java.io.Console; import java.io.IOException; import java.util.Arrays; /** Class to change the password of a user */ public class ChangePassword { public static void main (String[] args) throws IOException { // Obtain the console: (1) Console console = System.console(); if (console == null) { System.err.println(“No console available.”); return; } // Changing the password: (2) boolean noMatch = false; do { // Read the new password and its confirmation: char[] newPasswordSelected = console.readPassword(“Enter your new password: “); char[] newPasswordConfirmed = console.readPassword(“Confirm your new password: “); // Compare the supplied passwords: noMatch = newPasswordSelected.length == 0 || newPasswordConfirmed.length == 0 || !Arrays.equals(newPasswordSelected, newPasswordConfirmed); if (noMatch) { console.format(“Passwords don’t match. Please try again.%n”); } else { // Necessary code to change the password. console.format(“Password changed.”); } } while (noMatch); } }
Running the program:
> java ChangePassword Enter your new password: Confirm your new password: Password changed.
Object serialization allows the state of an object to be transformed into a sequence of bytes that can be converted back into a copy of the object (called deserialization). After deserialization, the object has the same state as it had when it was serialized, barring any data members that were not serializable. This mechanism is generally known as persistence—the serialized result of an object can be stored in a repository from which it can be later retrieved.
Java provides the object serialization facility through the ObjectInput and Object-Output interfaces, which allow the writing and reading of objects to and from I/O streams. These two interfaces extend the DataInput and DataOutput interfaces, respectively (Figure 20.1, p. 1235).
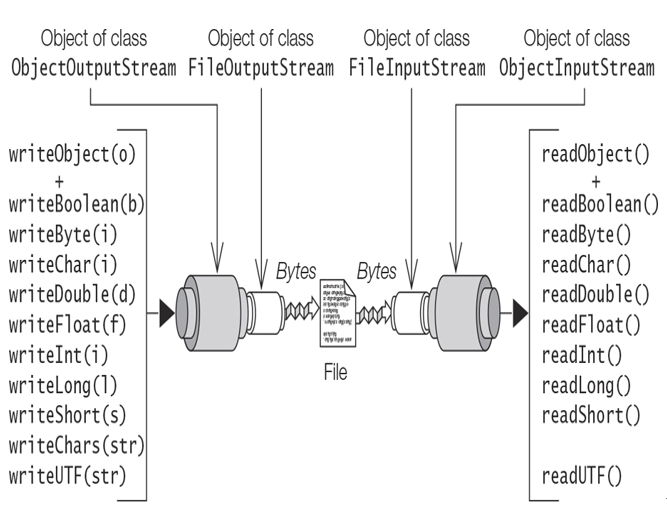
The ObjectOutputStream class and the ObjectInputStream class implement the Object-Output interface and the ObjectInput interface, respectively, providing methods to write and read binary representation of both objects as well as Java primitive values. Figure 20.9 gives an overview of how these classes can be chained to underlying streams and some selected methods they provide. The figure does not show the methods inherited from the abstract OutputStream and InputStream superclasses.
Figure 20.9 Object Stream Chaining
The read and write methods in the two classes can throw an IOException, and the read methods will throw an EOFException if an attempt is made to read past the end of the stream.
The ObjectOutputStream Class
The class ObjectOutputStream can write objects to any stream that is a subclass of the OutputStream—for example, to a file or a network connection (socket). An Object-OutputStream must be chained to an OutputStream using the following constructor:
For example, in order to store objects in a file and thus provide persistent storage for objects, an ObjectOutputStream can be chained to a FileOutputStream:
final void writeObject(Object obj) throws IOException
The writeObject() method can be used to write any object to a stream, including strings and arrays, as long as the object implements the java.io.Serializable interface, which is a marker interface with no methods. The String class, the primitive wrapper classes, and all array types implement the Serializable interface. A serializable object can be any compound object containing references to other objects, and all constituent objects that are serializable are serialized recursively when the compound object is written out. This is true even if there are cyclic references between the objects. Each object is written out only once during serialization. The following information is included when an object is serialized:
The class information needed to reconstruct the object
The values of all serializable non-transient and non-static members, including those that are inherited
A checked exception of the type java.io.NotSerializableException is thrown if a non-serializable object is encountered during the serialization process. Note also that objects of subclasses that extend a serializable class are always serializable.
Although formatting of values is covered extensively in Chapter 18, p. 1095, here we mention the support for formatting values provided by I/O streams. The PrintWriter class provides the format() methods and the printf() convenient methods to write formatted values. The printf() methods are functionally equivalent to the format() methods. As the methods return a PrintWriter, calls to these methods can be chained.
The printf() and the format() methods for printing formatted values are also provided by the PrintStream and the Console classes (p. 1256). The format() method is also provided by the String class (§8.4, p. 457). We assume familiarity with printing formatted values on the standard output stream by calling the printf() method on the System.out field which is an object of the PrintStream class (§1.9, p. 24).
PrintWriter format(String format, Object… args) PrintWriter format(Locale loc, String format, Object… args) PrintWriter printf(String format, Object… args) PrintWriter printf(Locale loc, String format, Object… args)
The String parameter format specifies how formatting will be done. It contains format specifiers that determine how each subsequent value in the variable arity parameter args will be formatted and printed. The resulting string from the formatting will be written to the current writer.
If the locale is specified, it is taken into consideration to format the args.
Any error in the format string will result in a runtime exception.
Writing Text Files
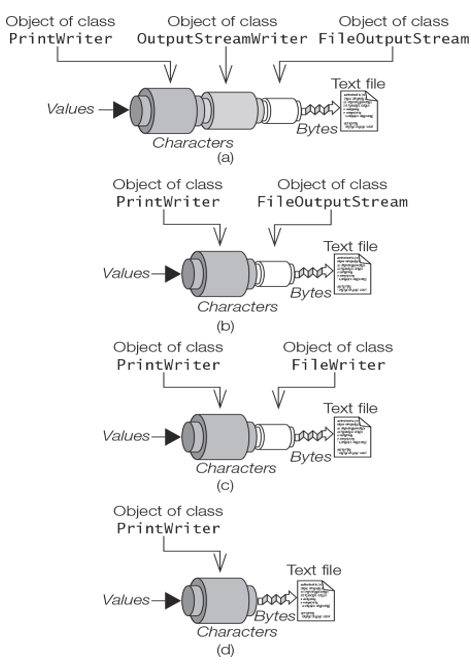
When writing text representation of values to a file using the default character encoding, any one of the following four procedures for setting up a PrintWriter can be used.
Setting up a PrintWriter based on an OutputStreamWriter which is chained to a FileOutputStream (Figure 20.4(a)):
Figure 20.4 Setting Up a PrintWriter to Write to a File
PrintWriter printWriter2 = new PrintWriter(outputFile, true);
The intermediate OutputStreamWriter to convert the characters using the default encoding is automatically supplied. The output buffer will also perform automatic line flushing.
Setting up a PrintWriter based on a FileWriter (Figure 20.4(c)):
Create a FileWriter which is a subclass of OutputStreamWriter:
PrintWriter printWriter4 = new PrintWriter(“info.txt”);
The underlying OutputStreamWriter is created to write the characters to the file in the default encoding, as shown in Figure 20.4(d). In this case, there is no automatic flushing by the println() and printf() methods.
If a specific character encoding is desired for the writer, the third procedure (Figure 20.4(c)) can be used, with the encoding being specified for the FileWriter:
Charset utf8 = Charset.forName(“UTF-8”); FileWriter fileWriter = new FileWriter(“info.txt”, utf8); PrintWriter printWriter5 = new PrintWriter(fileWriter, true);
This writer will use the UTF-8 character encoding to write the characters to the file. Alternatively, we can use a PrintWriter constructor that accepts a character encoding: