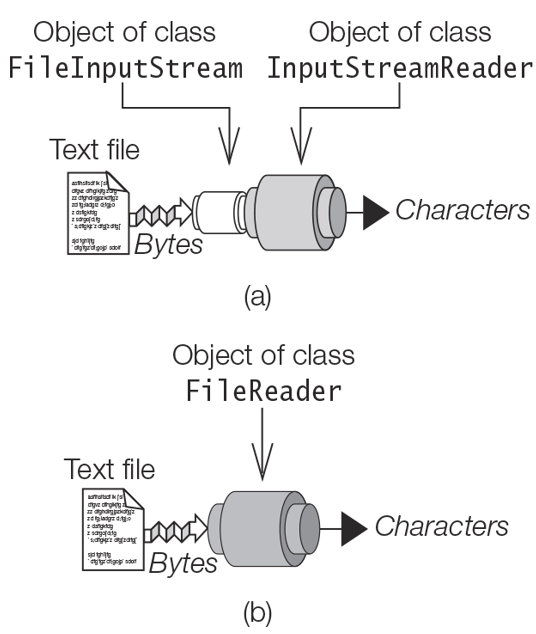
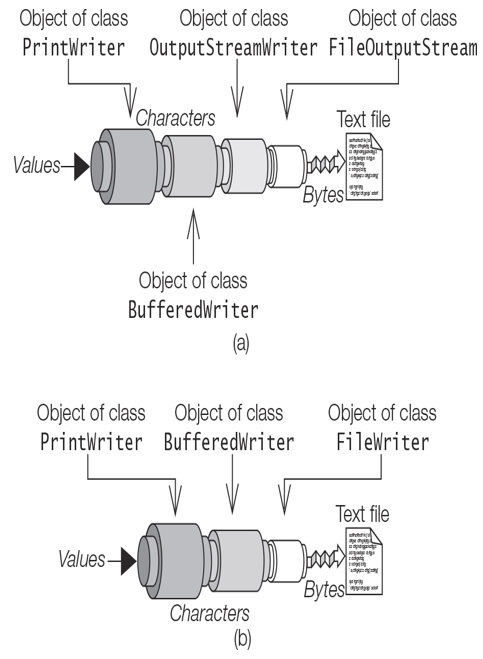
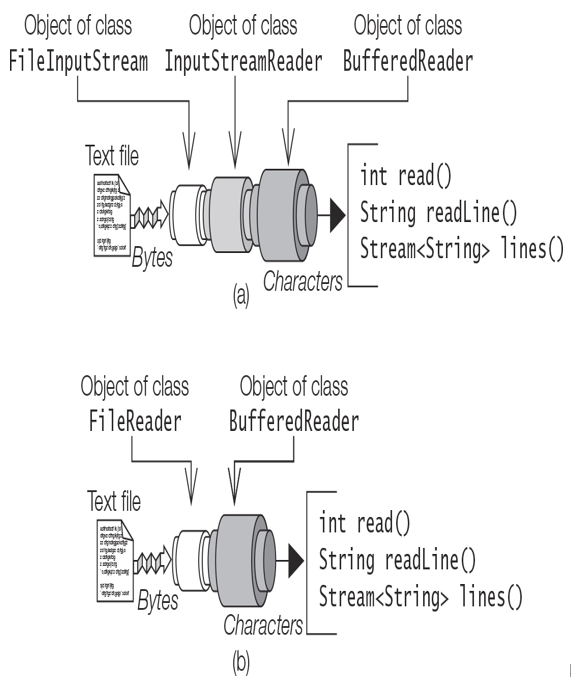
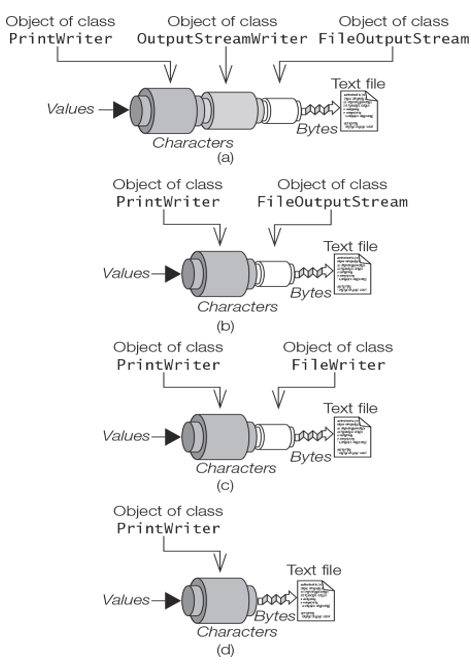
Viewing Dependencies
The Java Dependency Analysis tool, jdeps, is a versatile command-line tool for static analysis of dependencies between Java artifacts like class files and JARs. It can analyze dependencies at all levels: module, package, and class. It allows the results to be filtered and aggregated in various ways, even generating various graphs to illustrate its findings. It is an indispensable tool when migrating non-modular code to make use of the module system.
In this section, we confine our discussion to modular code—that is, either an exploded module directory with the compiled module code (e.g., mods/main) or a modular JAR (e.g., mlib/main.jar).
In this section, the results from some of the jdeps commands have been edited to fit the width of the page without any loss of information, or elided to shorten repetitious outputs.
Viewing Package-Level Dependencies
The jdeps command with no options, shown below, illustrates the default behavior of the tool. Line numbers have been added for illustrative purposes.
When presented with the root module directory mods/model (1), the default behavior of jdeps is to print the name of the module (2), the path to its location (3), its module descriptor (4), followed by its module dependencies (5), and lastly the package-level dependencies (6). The package-level dependency at (6) shows that the package com.passion.model in the model module depends on the java.lang package in the proverbial java.base module.
(1)
>jdeps mods/model
(2) model
(3) [file:…/adviceApp/mods/model/]
(4) requires mandated java.base (@17.0.2)
(5) model -> java.base
(6) com.passion.model -> java.lang java.base
The following jdeps command if let loose on the model.jar archive will print the same information for the model module, barring the difference in the file location:
>
jdeps mlib/model.jar
However, the following jdeps command with the main.jar archive gives an error:
>jdeps mlib/main.jar
Exception in thread “main” java.lang.module.FindException: Module controller
not found, required by main
at java.base/…
Dependency analysis cannot be performed on the main module by the jdeps tool because the modules the main module depends on cannot be found. In the case of the model module, which does not depend on any other user-defined module, the dependency analysis can readily be performed.
The two options –module-path (no short form) and –module (short form: -m) in the jdeps command below unambiguously specify the location of other modular JARs and the module to analyze, respectively. The format of the output is the same as before, and can be verified easily.
>jdeps –module-path mlib –module main
main
[file:…/adviceApp/mlib/main.jar]
requires controller
requires mandated java.base (@17.0.2)
main -> controller
main -> java.base
com.passion.main -> com.passion.controller controller
com.passion.main -> java.lang java.base
However, if one wishes to analyze all modules that the specified module depends on recursively, the –recursive option (short form: -R) can be specified. The output will be in the same format as before, showing the package-level dependencies for each module. The output from the jdeps command for each module is elided below, but has the same format we have seen previously.
>
jdeps –module-path mlib –module main –recursive
controller
…
main
…
model
…
view
…